
Improving Firestore Structure
The clothing store app I made was one of my first Swift projects, and I have improved my skills since then. While I am fond of it, I am planning to rework the app with better coding and architectural principles. A lot of what I plan is still an idealization but would be really cool if I end up finishing the project in the future.
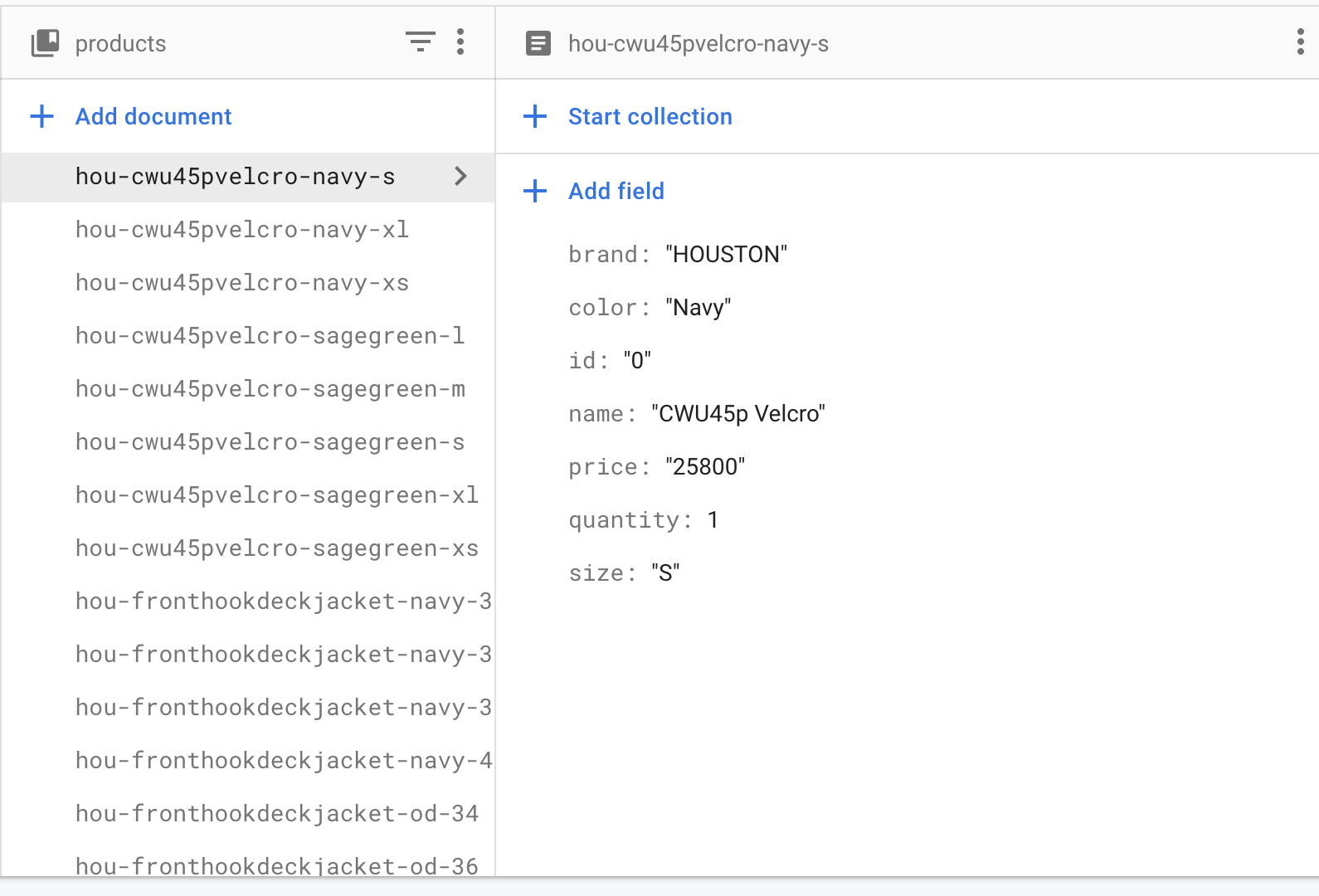
Above: My old database is a long list to get through
I want to rework my Firestore database.
Something new is that I am exploring the possibility of printing my own barcodes/qrcodes to stick to the products. Without considering my concern about the amount of hands-on labor this might take, I think it would make cash-registers much quicker and easier than before, and could also reduce accounting errors. Another big reason for this is that I discovered a sizable amount of errors some manufacturers made when labeling the correct codes on products, so using the codes they left on the products can’t be an option.

Above: Product tags could often be wrongly labeled by manufacturers
Creating the new Database
My original firebase would have one collection containing every existing product. This, is a very long list. To start, I wanted to divide products by brands. After some consideration, I am ultimately planning to proceed with this structure:
- Brand: Valley Apparel
- Category: Flight Jacket
- Name: MA1
- Price: 18800
- Color: [OD, Black, Navy]
- Size: [S, M, L, XL]
- Name: MA1
- Category: Flight Jacket
I favor having sizes and colors in arrays. This would also work with a qr/bar code schema because I plan on making my own, which gives me a lot of freedom (because I don’t have to make a document for every size-color variant, which eliminates a huge amount of necessary space). The codes would probablylook like this:
18800-hou-ma1-od-s


Above: And the barcode or QRcode would look like this
The structure here goes price-brand-product-colorway-size. I plan on using dictionaries to deal with shortened abbreviations for brand names.
Blog conclusion: I’m excited to start re-working my data because it will be cleaner and will perform better. When I come to a decision, I will fill in the data which should take less time than before.